

Author
Article written by Shivani Shah, CTO & Co-founder at Samp
Given the current market, there are so many tools with very mature workflows to annotate and manage AI training data. But at Samp we chose to develop custom tools in-house to perform this task, which can be very puzzling. The aim of this article is therefore to describe the thought process behind this choice, while exposing the underlying complexity of the task.
Domains like autonomous cars, mapping of geographical territories and indoor buildings ect also require annotation of large amounts of 3D lidar data. But this market is smaller than that for 2D images and the needs of annotation are also fragmented, so there are much fewer tools developed for the purpose of labelling point clouds.
What data annotation is needed on Point Clouds?
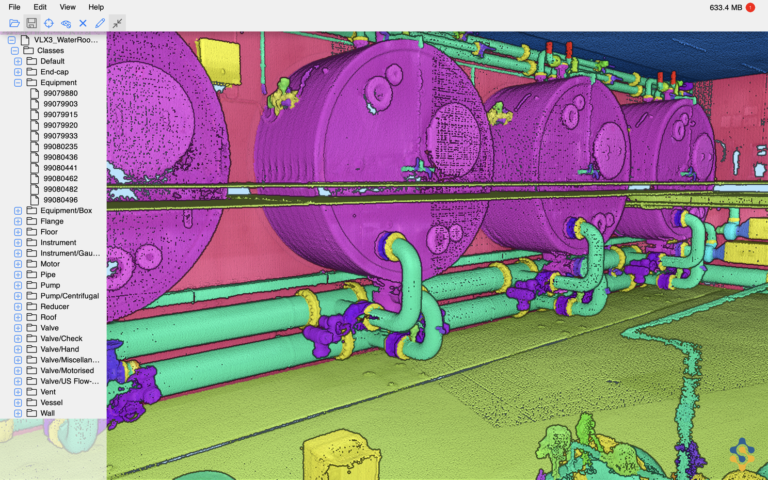
The role of 3D AI for the Samp ‘Shared reality’ product is to detect an instance of an object and also predict the semantic class of it, also known as Panoptic Segmentation. So for the data labelling, we need to separate each object from the scene and attach the instance and semantic label to it.
We started with open source softwares like Cloud Compare, and then moved to Leica Cyclone when the datasets got bigger. Such an annotation task requires domain expertise of knowing objects in the Industrial site, so it was important to choose software which the domain experts are comfortable with. But eventually we designed our own tool to perform the task.

1. Massive size of the industrial data
Since we started to handle real client data, we had to annotate scans which have billions of points per site! It is petabytes of point cloud data to be processed if all put together. This slowed down most of the operations and the data transfers between two locations itself could take hours.
Most of the AI data annotation tools support up to a few million points. This is sufficient for the market of autonomous cars, mainly because cars use very sparse point clouds. Whereas the industrial point clouds we have requires much higher density of points leading to very large size files.
With Industrial softwares like Cyclone, they start to significantly slow down with this data size. Adding lots of minutes of waiting time and then crashing eventually. Given they are not open source, it is also not possible to understand the bottlenecks or improve any features ourselves.
For goal of accelerating the whole annotation process, we identified following tasks which needed to be addressed:
- Enable the annotation tool to handle larger data files
- Centralise data pipeline to avoid a lot of data transfers
- Accelerate the speed of read, write and transfer of the data
With the insanely skilled team members at Samp, we managed to solve these objectives above by building our own tool for annotation which is able to handle much larger data files.
This lead to the very special in-house technical developments like:
- Custom file format. Our beloved ‘Samp-point-Z’. It is designed to have all information needed for AI training, for example object labels. Which reduced number of read and write operations.
- Custom Compression algorithm. It is custom designed specifically for the density of point clouds needed for the AI and visual quality of Samp products. It is better suited than Draco as there is no loss of data on read-write. It gave us about 30% more data compression than open formats like .e57.
- Centralising the data flow. By controlling the process end-to-end, we are able to design optimal ways to transfer data between different steps of the Annotation process. Starting from data verification, segmentation, labelling and quality checks for QaQC.
Where physical integrity meets information integrity
2. Data security
The Industrial data is sensitive and there are serious regulations in place to avoid any leakage of the asset information. This was always a challenge when transferring data to 3rd party tools. But in the newly designed process, we control the user authentication. Also the data never leaves the Samp server and tools which ensures better data security for the customers.
3. Speeding up the data annotation process by leveraging in-house AI.
It is a common practice in the 2D annotation tools to pre-segment the data using AI under the hood to facilitate selection of the regions for labelling. Similarly, the same analogy has been applied to 3D, where the AI built in-house has been leveraged in the annotation tool to pre-segment the data into clusters corresponding to the desired instance.
The major gain here is in the time as AI already does a lot of the heavy lifting reducing the time to half.
4. Handling data variations
As we’re deploying across different categories of heavy industries like water, waste, energy etc, we find some differences in the process. Typically in the taxonomy, data types, data formats, occlusion, density ect.
Having our own data annotation tool provides us enough flexibility to efficiently accommodate the evolving needs and help us scale across industries.
5. Productization and Human-in-the-loop
The vision for companies deploying computer vision models is to go from “Manual” to “Partial AI” to “Only AI“. However, mistakes here can have dangerous consequences for safety on these sites. So the humans need to verify and if needed correct the output from AI models before the final delivery.
By connecting together the data annotation tool to the Samp web platform, we have enabled the corrections capability for the client data… facilitating the “Human-in-the-loop”.
All the AI companies have their unique challenges for achieving the needed labelled data, would be very happy to connect and exchange on this subject.



