

Author
Article written by Shivani Shah, CTO & Co-founder at Samp
Compte tenu du marché actuel, il existe une multitude d’outils dotés de flux de travail très aboutis pour annoter et gérer les données d’entraînement de l’IA. Mais chez Samp, nous avons choisi de développer en interne des outils sur mesure pour accomplir cette tâche, ce qui peut paraître très surprenant. L’objectif de cet article est donc de décrire le raisonnement qui sous-tend ce choix, tout en mettant en lumière la complexité inhérente à cette tâche.
Des domaines tels que les voitures autonomes, la cartographie de territoires géographiques et de bâtiments intérieurs, etc. nécessitent également l'annotation de grandes quantités de données lidar 3D. Mais ce marché est plus restreint que celui des images 2D et les besoins en matière d'annotation sont également fragmentés, de sorte qu'il existe beaucoup moins d'outils développés dans le but d'étiqueter des nuages de points.
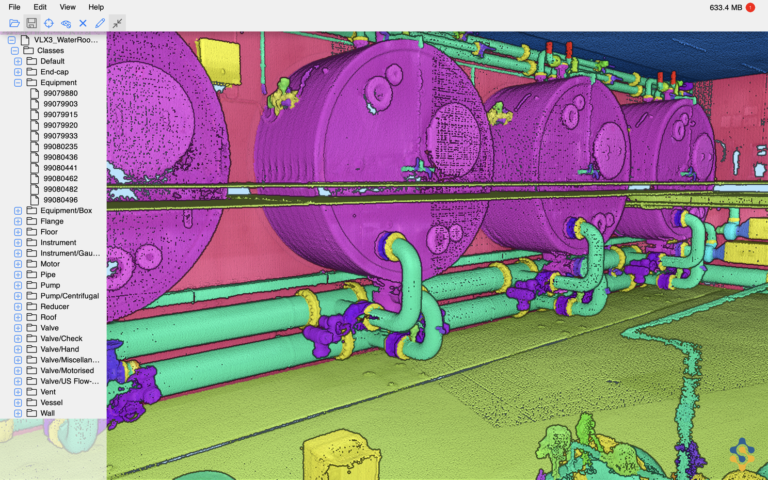
Quelle annotation des données est nécessaire sur les nuages de points ?
Le rôle de l'IA 3D pour le produit « Shared reality » de Samp consiste à détecter une instance d'un objet et à prédire sa classe sémantique, ce que l'on appelle également la segmentation panoptique. Pour l'étiquetage des données, nous devons donc séparer chaque objet de la scène et lui attribuer une instance et une étiquette sémantique.
Nous avons commencé avec des logiciels open source tels que Cloud Compare, puis sommes passés à Leica Cyclone lorsque les ensembles de données ont pris de l'ampleur. Une telle tâche d'annotation nécessite une expertise du domaine pour connaître les objets présents sur le site industriel ; il était donc important de choisir un logiciel avec lequel les experts du domaine se sentent à l'aise. Mais nous avons finalement conçu notre propre outil pour effectuer cette tâche.

1. Volume colossal des données industrielles
Depuis que nous avons commencé à traiter les données réelles de nos clients, nous avons dû annoter des scans contenant des milliards de points par site ! Au total, cela représente des pétaoctets de données de nuages de points à traiter. Cela a ralenti la plupart des opérations, et les transferts de données entre deux sites pouvaient eux-mêmes prendre des heures.
La plupart des outils d'annotation de données par IA prennent en charge jusqu'à quelques millions de points. Cela est suffisant pour le marché des voitures autonomes, principalement parce que les voitures utilisent des nuages de points très clairsemés. En revanche, les nuages de points industriels dont nous disposons nécessitent une densité de points bien plus élevée, ce qui se traduit par des fichiers de très grande taille.
Avec des logiciels industriels comme Cyclone, les performances commencent à baisser considérablement face à un tel volume de données. Cela entraîne de longues minutes d'attente, puis finit par provoquer des plantages. Comme ces logiciels ne sont pas open source, il n'est pas non plus possible de comprendre les goulots d'étranglement ni d'améliorer nous-mêmes leurs fonctionnalités.
Afin d'accélérer l'ensemble du processus d'annotation, nous avons identifié les tâches suivantes qui devaient être traitées :
- Permettre à l'outil d'annotation de traiter des fichiers de données plus volumineux
- Centraliser le pipeline de données pour éviter de nombreux transferts de données
- Accélérer la vitesse de lecture, d'écriture et de transfert des données
Grâce aux membres de l'équipe extrêmement compétents de Samp, nous avons réussi à atteindre ces objectifs en développant notre propre outil d'annotation, capable de traiter des fichiers de données beaucoup plus volumineux.
Cela a donné lieu à des développements techniques internes très particuliers, tels que :
- Un format de fichier personnalisé. Notre cher « Samp-point-Z ». Il est conçu pour contenir toutes les informations nécessaires à l'entraînement de l'IA, par exemple les étiquettes d'objets. Ce qui a permis de réduire le nombre d'opérations de lecture et d'écriture.
- Un algorithme de compression sur mesure. Il est spécialement conçu pour la densité des nuages de points requise par l’IA et la qualité visuelle des produits Samp. Il est plus adapté que Draco, car il n’y a aucune perte de données lors de la lecture-écriture. Il nous a permis d’obtenir environ 30 % de compression en plus par rapport aux formats ouverts tels que .e57.
- Centralisation du flux de données. En contrôlant le processus de bout en bout, nous sommes en mesure de concevoir des méthodes optimales pour transférer les données entre les différentes étapes du processus d'annotation. Cela va de la vérification des données à la segmentation, en passant par l'étiquetage et les contrôles de qualité pour le QaQC.
Quand l'intégrité physique rencontre l'intégrité de l'information
2. Sécurité des données
Les données industrielles sont sensibles et font l'objet de réglementations strictes visant à éviter toute fuite d'informations sur les actifs. Cela a toujours constitué un défi lors du transfert de données vers des outils tiers. Mais dans le nouveau processus, nous contrôlons l'authentification des utilisateurs. De plus, les données ne quittent jamais le serveur et les outils Samp, ce qui garantit une meilleure sécurité des données pour les clients.
3. Accélération du processus d'annotation des données grâce à l'IA interne.
Il est courant, dans les outils d'annotation 2D, de pré-segmenter les données à l'aide d'une IA intégrée afin de faciliter la sélection des zones à étiqueter. De la même manière, ce principe a été appliqué à la 3D, où l'IA développée en interne a été intégrée à l'outil d'annotation pour pré-segmenter les données en clusters correspondant à l'instance souhaitée.
Le principal avantage réside ici dans le gain de temps, car l'IA effectue déjà une grande partie du travail fastidieux, réduisant ainsi le temps nécessaire de moitié.
4. Gestion des variations des données
Comme nous déployons nos solutions dans différentes catégories d'industries lourdes telles que l'eau, les déchets, l'énergie, etc., nous constatons certaines différences dans le processus. Généralement au niveau de la taxonomie, des types de données, des formats de données, de l'occlusion, de la densité, etc.
Disposer de notre propre outil d'annotation des données nous offre suffisamment de flexibilité pour répondre efficacement aux besoins en constante évolution et nous aide à nous adapter à l'ensemble des secteurs.
5. Commercialisation et intervention humaine
La vision des entreprises qui déploient des modèles de vision par ordinateur est de passer du « manuel » à l’« IA partielle », puis à l’« IA seule ». Cependant, les erreurs peuvent avoir des conséquences dangereuses pour la sécurité sur ces sites. Les humains doivent donc vérifier et, si nécessaire, corriger les résultats des modèles d’IA avant la livraison finale.
En connectant l'outil d'annotation de données à la plateforme web Samp, nous avons activé la fonctionnalité de correction pour les données des clients… facilitant ainsi l'« intervention humaine ».
Toutes les entreprises spécialisées dans l'IA sont confrontées à des défis spécifiques pour obtenir les données étiquetées nécessaires ; je serais ravi d'échanger avec vous sur ce sujet.



