Author
Article written by Shivani Shah, CTO & Co-founder at Samp
Angesichts der aktuellen Marktlage gibt es zahlreiche Tools mit ausgereiften Workflows zur Annotation und Verwaltung von KI-Trainingsdaten. Bei Samp haben wir uns jedoch dafür entschieden, für diese Aufgabe eigene Tools intern zu entwickeln, was auf den ersten Blick verwirrend erscheinen mag. Ziel dieses Artikels ist es daher, die Überlegungen hinter dieser Entscheidung zu beschreiben und gleichzeitig die zugrunde liegende Komplexität der Aufgabe aufzuzeigen.
Bereiche wie autonome Fahrzeuge, die Kartierung geografischer Gebiete und von Innenräumen von Gebäuden usw. erfordern ebenfalls die Annotation großer Mengen an 3D-Lidar-Daten. Da dieser Markt jedoch kleiner ist als der für 2D-Bilder und die Anforderungen an die Annotation zudem fragmentiert sind, gibt es weitaus weniger Tools, die speziell für die Beschriftung von Punktwolken entwickelt wurden.
Welche Datenannotation ist bei Punktwolken erforderlich?
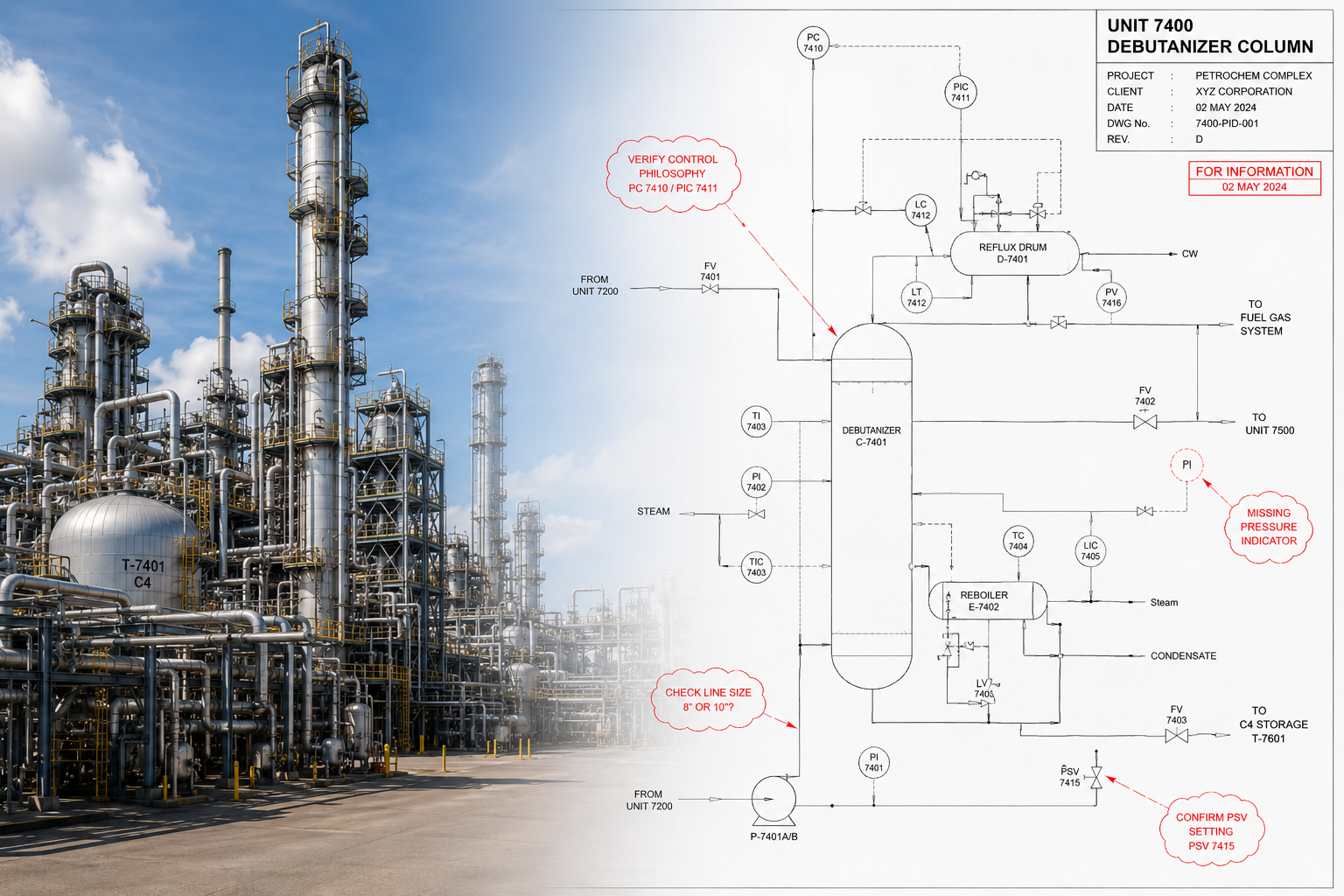
Die Rolle der 3D-KI für das Produkt „Shared Reality“ von Samp besteht darin, eine Instanz eines Objekts zu erkennen und dessen semantische Klasse vorherzusagen, was auch als Panoptische Segmentierung bezeichnet wird. Für die Datenkennzeichnung müssen wir also jedes Objekt aus der Szene herauslösen und ihm die Instanz- sowie die semantische Kennzeichnung zuweisen.
Wir begannen mit Open-Source-Software wie Cloud Compare und wechselten dann zu Leica Cyclone, als die Datensätze größer wurden. Eine solche Annotationsaufgabe erfordert Fachwissen über Objekte am Industriestandort, daher war es wichtig, eine Software zu wählen, mit der die Fachexperten vertraut sind. Letztendlich haben wir jedoch unser eigenes Tool entwickelt, um diese Aufgabe zu bewältigen.

1. Die enorme Menge an Industriedaten
Seit wir begonnen haben, mit echten Kundendaten zu arbeiten, mussten wir Scans mit Milliarden von Punkten pro Standort annotieren! Zusammengenommen sind das Petabytes an Punktwolkendaten, die verarbeitet werden müssen. Dies verlangsamte die meisten Vorgänge, und allein die Datenübertragung zwischen zwei Standorten konnte Stunden dauern.
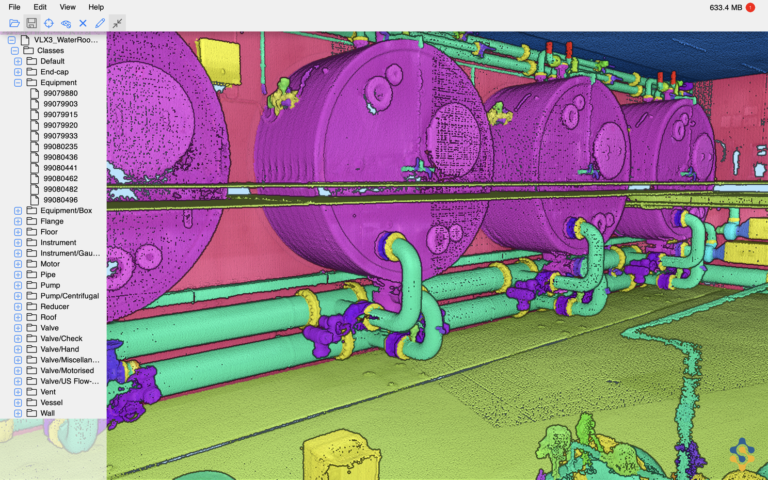
Die meisten KI-Tools zur Datenannotation unterstützen nur bis zu einigen Millionen Punkten. Dies reicht für den Markt der autonomen Fahrzeuge aus, vor allem weil Autos sehr spärliche Punktwolken verwenden. Die industriellen Punktwolken, mit denen wir arbeiten, erfordern hingegen eine viel höhere Punktdichte, was zu sehr großen Dateien führt.
Bei industrieller Software wie Cyclone kommt es bei dieser Datenmenge zu erheblichen Verlangsamungen. Es kommt zu Wartezeiten von mehreren Minuten, und schließlich stürzt das Programm ab. Da es sich nicht um Open-Source-Software handelt, ist es zudem nicht möglich, die Engpässe zu verstehen oder Funktionen selbst zu verbessern.
Um den gesamten Annotationsprozess zu beschleunigen, haben wir folgende Aufgaben identifiziert, die angegangen werden mussten:
- Das Annotationstool für die Verarbeitung größerer Dateien befähigen
- Zentralisierung der Datenpipeline, um umfangreiche Datenübertragungen zu vermeiden
- Beschleunigung des Lesens, Schreibens und der Übertragung der Daten
Mit den unglaublich kompetenten Teammitgliedern bei Samp ist es uns gelungen, die oben genannten Ziele zu erreichen, indem wir unser eigenes Annotationstool entwickelt haben, das viel größere Datendateien verarbeiten kann.
Dies führte zu ganz besonderen internen technischen Entwicklungen wie:
- Ein benutzerdefiniertes Dateiformat. Unser geliebtes „Samp-point-Z“. Es ist so konzipiert, dass es alle für das KI-Training erforderlichen Informationen enthält, zum Beispiel Objektbezeichnungen. Dadurch konnte die Anzahl der Lese- und Schreibvorgänge reduziert werden.
- Ein eigener Komprimierungsalgorithmus. Er wurde speziell für die Dichte der Punktwolken entwickelt, die für die KI und die visuelle Qualität der Samp-Produkte benötigt werden. Er ist besser geeignet als Draco, da beim Lesen und Schreiben keine Daten verloren gehen. Er ermöglichte uns eine um etwa 30 % höhere Datenkomprimierung als offene Formate wie .e57.
- Zentralisierung des Datenflusses. Durch die durchgängige Steuerung des Prozesses sind wir in der Lage, optimale Wege für den Datentransfer zwischen den verschiedenen Schritten des Annotationsprozesses zu entwerfen. Angefangen bei der Datenverifizierung über die Segmentierung und Beschriftung bis hin zu Qualitätsprüfungen für QaQC.
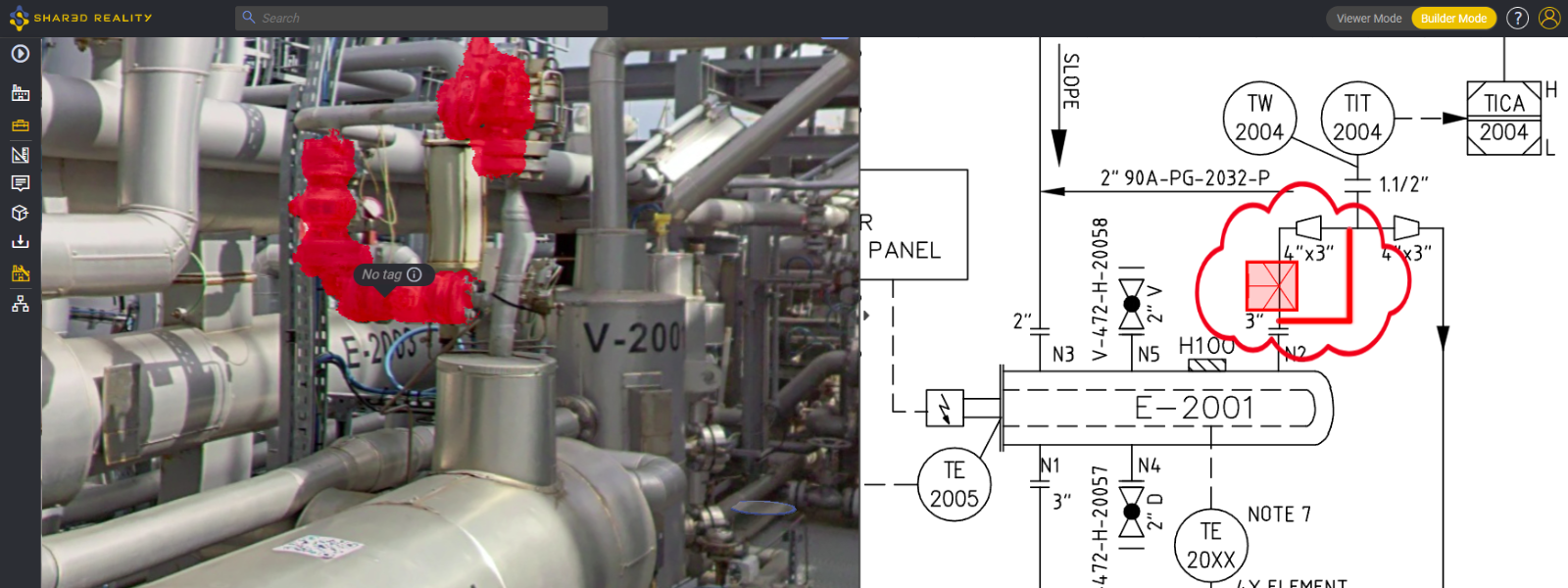
Wo physische Integrität auf Informationsintegrität trifft
2. Datensicherheit
Industriedaten sind sensibel, und es gelten strenge Vorschriften, um jeglichen Verlust von Vermögensinformationen zu verhindern. Dies war bei der Übertragung von Daten an Tools von Drittanbietern stets eine Herausforderung. Im neu gestalteten Prozess kontrollieren wir jedoch die Benutzerauthentifizierung. Zudem verlassen die Daten niemals den Samp-Server und die Samp-Tools, was den Kunden eine höhere Datensicherheit gewährleistet.
3. Beschleunigung des Datenannotationsprozesses durch den Einsatz interner KI.
Bei 2D-Annotationstools ist es gängige Praxis, die Daten mithilfe von KI im Hintergrund vorab zu segmentieren, um die Auswahl der zu beschriftenden Bereiche zu erleichtern. In ähnlicher Weise wurde dies auch auf 3D übertragen, wo die intern entwickelte KI im Annotationstool genutzt wird, um die Daten in Cluster zu segmentieren, die der gewünschten Instanz entsprechen.
Der größte Vorteil liegt hier in der Zeitersparnis, da die KI bereits einen Großteil der Arbeit übernimmt und den Zeitaufwand so um die Hälfte reduziert.
4. Umgang mit Datenvariationen
Da wir in verschiedenen Bereichen der Schwerindustrie wie Wasser, Abfall, Energie usw. tätig sind, stellen wir einige Unterschiede im Prozess fest. Typischerweise betreffen diese die Taxonomie, Datentypen, Datenformate, Okklusion, Dichte usw.
Unser eigenes Datenannotationstool bietet uns genügend Flexibilität, um den sich wandelnden Anforderungen effizient gerecht zu werden und uns dabei zu helfen, branchenübergreifend zu skalieren.
5. Produktisierung und Human-in-the-Loop
Die Vision für Unternehmen, die Computer-Vision-Modelle einsetzen, ist der Übergang von „manuell“ über „teilweise KI“ hin zu „nur KI“. Fehler können hier jedoch gefährliche Folgen für die Sicherheit an diesen Standorten haben. Daher müssen Menschen die Ergebnisse der KI-Modelle vor der endgültigen Auslieferung überprüfen und bei Bedarf korrigieren.
Durch die Anbindung des Datenannotationstools an die Samp-Webplattform haben wir die Korrekturfunktion für die Kundendaten ermöglicht … und damit den „Human-in-the-Loop“-Ansatz unterstützt.
Alle KI-Unternehmen stehen vor ihren ganz eigenen Herausforderungen bei der Beschaffung der benötigten gelabelten Daten. Ich würde mich sehr freuen, mich mit Ihnen zu vernetzen und mich zu diesem Thema auszutauschen.