Author
Article written by Shivani Shah, CTO & Co-founder at Samp
Mevcut piyasa koşulları göz önüne alındığında, yapay zeka eğitim verilerini etiketlemek ve yönetmek için oldukça olgun iş akışlarına sahip pek çok araç bulunmaktadır. Ancak Samp olarak, bu görevi yerine getirmek için şirket içinde özel araçlar geliştirmeyi tercih ettik; bu da oldukça kafa karıştırıcı bir durum olabilir. Dolayısıyla bu makalenin amacı, bu seçimin ardındaki düşünce sürecini açıklamak ve aynı zamanda görevin altında yatan karmaşıklığı ortaya koymaktır.
Otonom araçlar, coğrafi bölgelerin ve kapalı binaların haritalandırılması gibi alanlar da büyük miktarda 3D lidar verisinin etiketlenmesini gerektirir. Ancak bu pazar, 2D görüntüler için olan pazardan daha küçüktür ve etiketleme ihtiyaçları da parçalıdır, bu nedenle nokta bulutlarını etiketlemek amacıyla geliştirilmiş araçların sayısı çok daha azdır.
Nokta bulutlarında hangi veri etiketlemesi gereklidir?
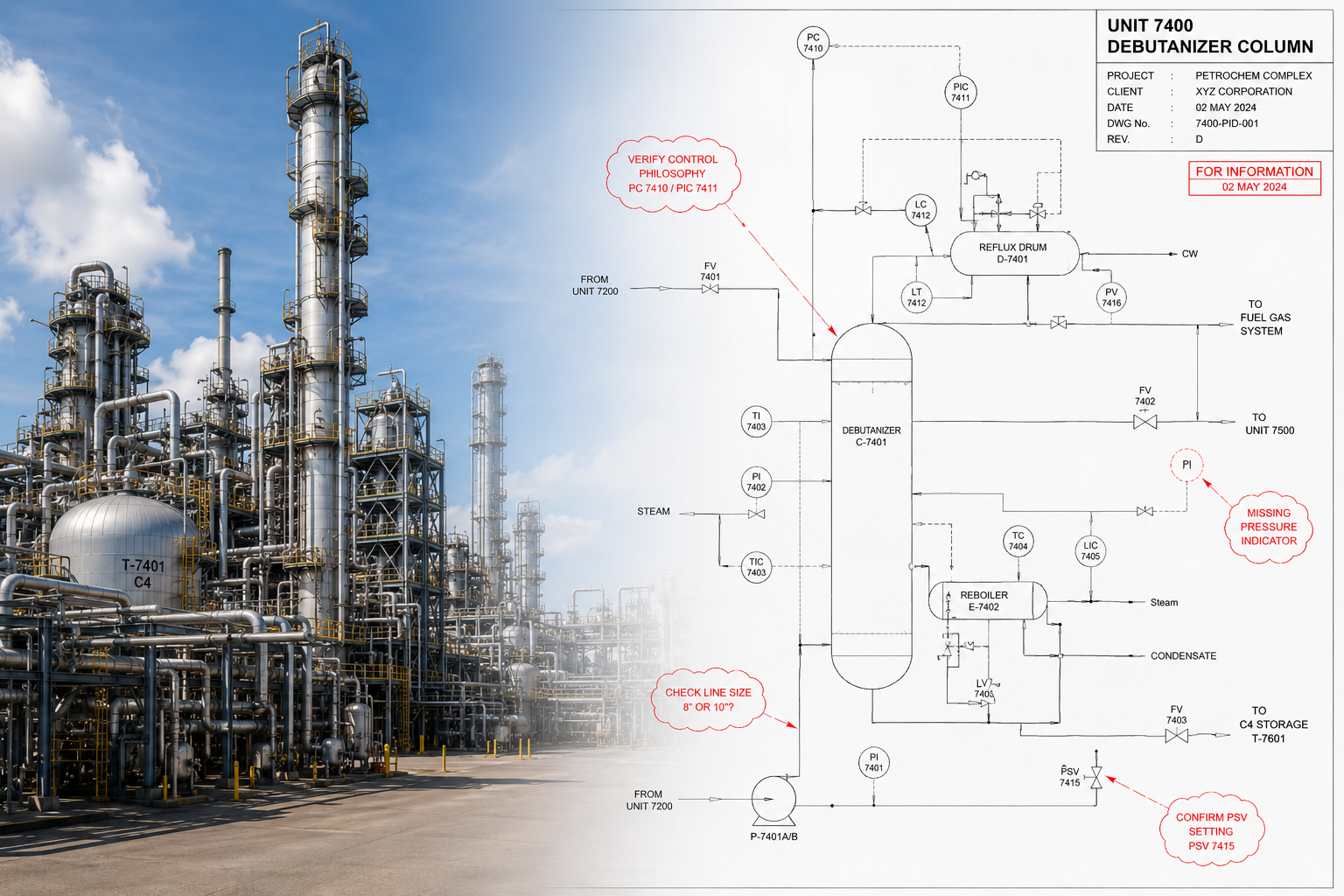
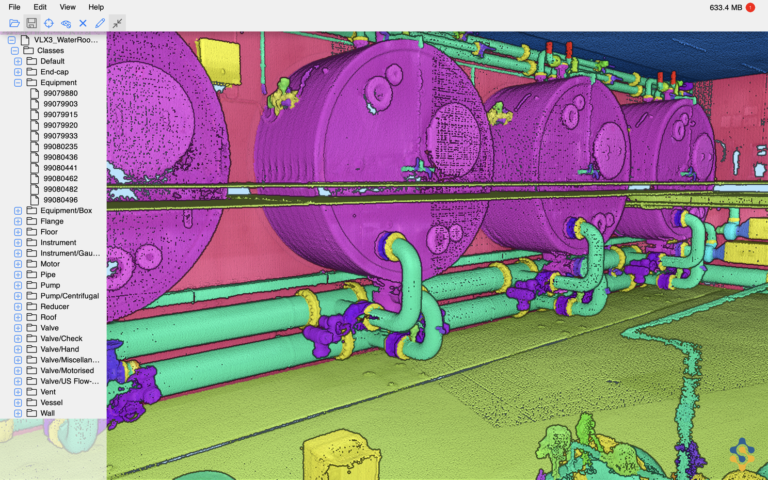
Samp'ın "Shared reality" ürünü için 3D AI'nın rolü, bir nesnenin örneğini tespit etmek ve aynı zamanda onun anlamsal sınıfını tahmin etmektir; bu, Panoptic Segmentation olarak da bilinir. Dolayısıyla veri etiketleme için her nesneyi sahneden ayırmamız ve ona örnek ve anlamsal etiketi eklememiz gerekir.
Cloud Compare gibi açık kaynaklı yazılımlarla başladık, ardından veri kümeleri büyüdüğünde Leica Cyclone'a geçtik. Bu tür bir etiketleme görevi, endüstriyel sahadaki nesneleri bilmek için alan uzmanlığı gerektirir, bu nedenle alan uzmanlarının rahat kullanabileceği bir yazılım seçmek önemliydi. Ancak sonunda bu görevi yerine getirmek için kendi aracımızı tasarladık.

1. Endüstriyel verilerin devasa boyutu
Gerçek müşteri verilerini işlemeye başladığımızdan beri, her bir lokasyon için milyarlarca noktadan oluşan taramaları etiketlemek zorunda kaldık! Bunların hepsi bir araya getirildiğinde işlenmesi gereken petabaytlarca nokta bulutu verisi ortaya çıkıyor. Bu durum işlemlerin çoğunu yavaşlattı ve iki konum arasındaki veri aktarımları saatler sürebiliyordu.
Çoğu AI veri etiketleme aracı, birkaç milyon noktaya kadar desteklemektedir. Bu, otonom araç pazarı için yeterlidir, çünkü araçlar genellikle çok seyrek nokta bulutları kullanır. Oysa bizim sahip olduğumuz endüstriyel nokta bulutları, çok daha yüksek nokta yoğunluğu gerektirir ve bu da çok büyük boyutlu dosyalara yol açar.
Cyclone gibi endüstriyel yazılımlar, bu veri boyutunda önemli ölçüde yavaşlamaya başlıyor. Bekleme süresi dakikalarca uzuyor ve sonunda çöküyor. Açık kaynaklı olmadıkları için, darboğazları anlamak veya özellikleri kendimiz iyileştirmek de mümkün değil.
Tüm anotasyon sürecini hızlandırmak amacıyla, ele alınması gereken aşağıdaki görevleri belirledik:
- Anotasyon aracının daha büyük veri dosyalarını işleyebilmesini sağlamak
- Çok sayıda veri aktarımını önlemek için veri boru hattını merkezileştirmek
- Verilerin okunma, yazılma ve aktarılma hızını artırmak
Samp'ın son derece yetenekli ekip üyeleriyle, çok daha büyük veri dosyalarını işleyebilen kendi anotasyon aracımızı geliştirerek yukarıdaki hedefleri çözmeyi başardık.
Bu, aşağıdakiler gibi çok özel şirket içi teknik gelişmelere yol açtı:
- Özel dosya formatı. Sevgili "Samp-point-Z"miz. AI eğitimi için gerekli tüm bilgileri, örneğin nesne etiketlerini içerecek şekilde tasarlanmıştır. Bu sayede okuma ve yazma işlemlerinin sayısı azalmıştır.
- Özel Sıkıştırma algoritması. Bu algoritma, yapay zeka için gerekli nokta bulutlarının yoğunluğu ve Samp ürünlerinin görsel kalitesi için özel olarak tasarlanmıştır. Okuma-yazma sırasında veri kaybı olmadığı için Draco'dan daha uygundur. Bize .e57 gibi açık formatlara göre yaklaşık %30 daha fazla veri sıkıştırması sağladı.
- Veri akışını merkezileştirme. Süreci uçtan uca kontrol ederek, Annotation sürecinin farklı adımları arasında veri aktarımı için en uygun yöntemleri tasarlayabiliyoruz. Veri doğrulama, segmentasyon, etiketleme ve QaQC için kalite kontrolleriyle başlıyor.
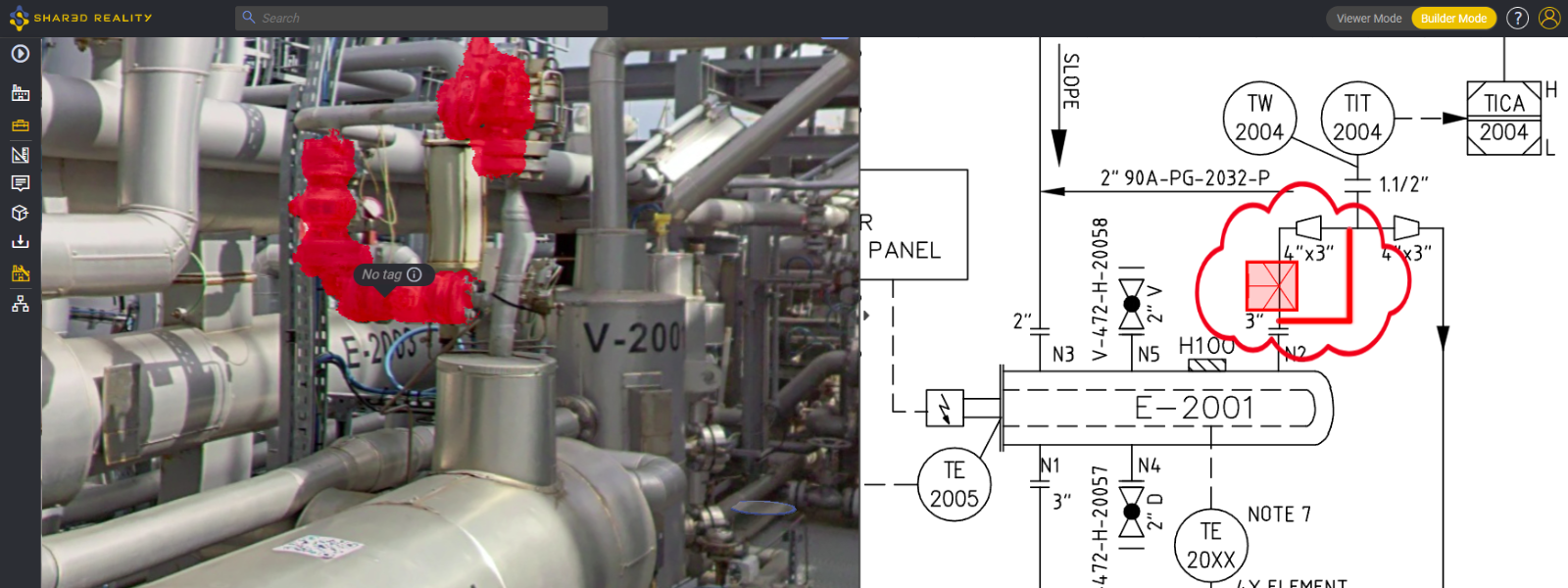
Fiziksel bütünlüğün bilgi bütünlüğü ile buluştuğu yer
2. Veri güvenliği
Endüstriyel veriler hassas niteliktedir ve varlık bilgilerinin sızmasını önlemek için ciddi düzenlemeler mevcuttur. Bu durum, verilerin üçüncü taraf araçlara aktarılması sırasında her zaman bir zorluk oluşturmuştur. Ancak yeni tasarlanan süreçte, kullanıcı kimlik doğrulamasını biz kontrol ediyoruz. Ayrıca veriler hiçbir zaman Samp sunucusu ve araçlarından dışarı çıkmaz, bu da müşteriler için daha iyi veri güvenliği sağlar.
3. Şirket içi yapay zekayı kullanarak veri anotasyon sürecini hızlandırma.
2D anotasyon araçlarında, etiketleme için bölgelerin seçimini kolaylaştırmak amacıyla arka planda yapay zeka kullanılarak verilerin önceden segmentlere ayrılması yaygın bir uygulamadır. Benzer şekilde, aynı mantık 3D'ye de uygulanmış ve anotasyon aracında şirket içi yapay zeka kullanılarak veriler istenen örneğe karşılık gelen kümelere önceden segmentlere ayrılmıştır.
Buradaki en büyük kazanç zamandır, çünkü AI zaten işin büyük bir kısmını üstlenerek süreyi yarıya indirir.
4. Veri varyasyonlarının ele alınması
Su, atık, enerji vb. gibi farklı ağır sanayi kategorilerinde faaliyet gösterdiğimiz için, süreçte bazı farklılıklar görüyoruz. Tipik olarak taksonomi, veri türleri, veri formatları, örtülme, yoğunluk vb. alanlarda.
Kendi veri anotasyon aracımıza sahip olmak, bize gelişen ihtiyaçları verimli bir şekilde karşılayacak ve sektörler arasında ölçeklendirme yapmamıza yardımcı olacak yeterli esnekliği sağlıyor.
5. Ürünleştirme ve İnsan Katılımı
Bilgisayar görme modellerini kullanan şirketlerin vizyonu, "Manuel"den "Kısmi AI"ye ve oradan da "Sadece AI"ye geçmektir. Ancak, buradaki hatalar bu sahaların güvenliği açısından tehlikeli sonuçlar doğurabilir. Bu nedenle, insanlar nihai teslimattan önce AI modellerinin çıktılarını doğrulamalı ve gerekirse düzeltmelidir.
Veri etiketleme aracını Samp web platformuna bağlayarak, müşteri verileri için düzeltme özelliğini etkinleştirdik ve böylece "İnsan Katılımı"nı kolaylaştırdık.
Tüm AI şirketleri, gerekli etiketli verileri elde etmek için kendine özgü zorluklarla karşı karşıyadır; bu konuda bağlantı kurup fikir alışverişinde bulunmaktan büyük mutluluk duyarız.